
Pockets of Replicability (Post#5)
A series of short articles on finance research replicability. On this issue: the debate about replication of asset pricing anomalies.

In the first post of this series, I mentioned two papers that look into whether asset pricing anomalies survive replication. In this post, we look at the overall discussion on the replicability of asset pricing anomalies.

Hou, Xue and Zhang: Most Anomalies Fail to Replicate
The first one is an influential paper in the recent replicability debate in empirical asset pricing: Hou, Xue and Zhang’s (2020) Replicating Anomalies. Their conclusion is stark: once you use stricter procedures, such as value-weighted returns, using NYSE breakpoints, and controls that reduce the influence of microcaps, most published anomalies no longer look very convincing. In their sample of 452 anomalies, 65% fail the standard single-test hurdle, and 82% fail once they impose a higher multiple-testing threshold. Their broader message is hard to miss: capital markets may be much more efficient than the anomalies literature had led us to believe. Among the anomalies that they find replicate well are value, momentum, investment and profitability.
Our key finding is that most anomalies fail to replicate, falling short of currently acceptable standards for empirical finance. First, of the 452 anomalies, 65% cannot clear the single test hurdle of |t|≥1.96. The key word is “microcaps.” Microcaps represent only 3.2% of the aggregate market capitalization but 60.7% of the number of stocks. Microcaps have the highest equal-weighted returns and the largest cross-sectional dispersions in returns and in anomaly variables. Many original studies overweight microcaps via equal-weighted returns and often with NYSE-Amex-NASDAQ breakpoints in portfolio sorts. Hundreds of studies perform cross-sectional regressions of returns on anomaly variables, mostly with ordinary least squares, which are highly sensitive to microcap outliers.
Jensen, Kelly, and Pedersen: The Zoo Looks More Alive Than You Think
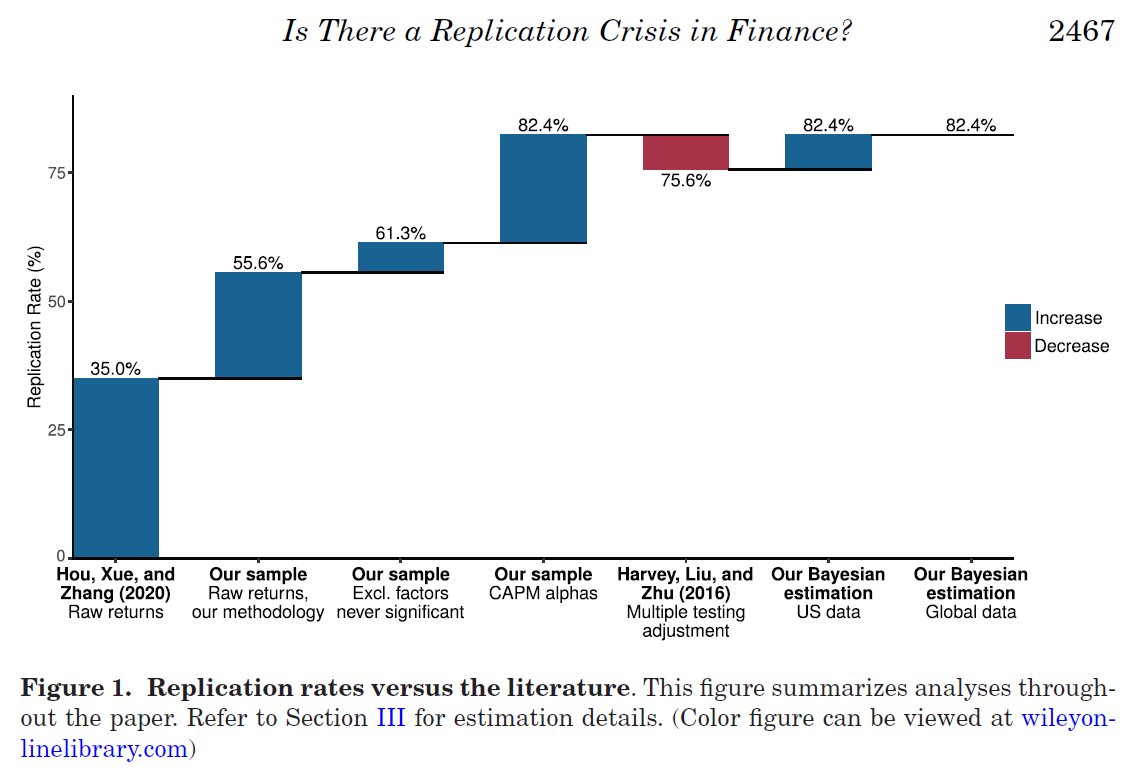
The second one is a later paper by Jensen, Kelly, and Pedersen (2023), Is There a Replication Crisis in Finance?, which pushes back and arrives at a very different conclusion. They begin by distinguishing two challenges in finance research replicability. The first is internal validity: do results survive replication under slightly different data and methods? The second is external validity: even if they do, are they just the product of multiple testing and p-hacking?
They propose a Bayesian framework to study anomalies in light of these two challenges. Their approach also has one crucial difference relative to Hou, Xue and Zhang, in that they propose to look at the anomalies alphas relative to the CAPM, instead of looking at returns.1 They also argue that the factor zoo should not be treated as a giant list of unrelated t-stats. Many factors are closely related, and a joint Bayesian framework can use that dependence to separate false discoveries from genuinely recurring signals more efficiently than blunt multiple-testing corrections. They propose to group anomalies into “themes” using their Bayesian modeling approach, and classify anomalies algorithmically into 13 themes that have high correlation and economic similarity. On their numbers, replication rates are much higher compared to Hou, Xue, and Zhang. For example, using their sample and CAPM alphas, they find that 82.4% anomalies replicate. They also extend the analysis to a large international sample and argue that the majority of factors work out of sample across 93 countries.
López de Prado and Fabozzi: Are we Even Asking the Right Question?
A recent paper by López de Prado and Fabozzi adds another twist to this debate by arguing that even the more optimistic attempts to estimate false discovery rates from the cross-section of published factor results face a deeper identification problem. Their point is not simply that finance researchers test too many things. It is that the published statistic is often the winner of an unobserved search over many specifications, so the observed cross-section is no longer generated by the “single-trial” experiment assumed by empirical-Bayes, local-FDR, or hierarchical-Bayes approaches. In that sense, they are challenging not just the pessimism of Hou, Xue, and Zhang, but also the optimism of Jensen, Kelly, and Pedersen: once latent search and selection are present, the prevalence of genuine factors cannot be recovered from in-sample reported statistics alone unless one explicitly models that search process or brings in genuinely independent validation data. Under their own maintained search-adjusted model, the implied false discovery rate is much higher than in the optimistic recent literature. Whether one buys all of their assumptions or not, the paper usefully sharpens the real issue: this is not only a fight about t-statistics, microcaps, or Bayesian estimation, but about what statistical experiment we think actually generated the factor zoo in the first place.

Final Thoughts
My own takeaway is that these papers are best read together. Hou, Xue, and Zhang are a useful corrective to an earlier literature that had become too comfortable with marginal t-statistics and too casual about robustness. Jensen, Kelly, and Pedersen are a reminder that once we bring in risk adjustment, dependence across factors, and international evidence, the case against the entire anomalies literature becomes much less clear-cut. López de Prado and Fabozzi, in turn, force the debate onto even deeper ground by asking whether the data we observe can identify the false discovery rate at all without modeling the hidden search process that generated the published result.
So the right conclusion is probably neither “the zoo is dead” nor “everything replicates.” It is that finance has likely discovered a fair amount of real structure in returns, but much less cleanly, and much less definitively, than the original papers often suggest.
The idea being that the CAPM “…is the clearest theoretical benchmark model that is not mechanically linked to other so-called anomalies in the list of replicated factors.”